What is VENES?
V Vuejs|
E Express|
N Nodejs|
ES Elasticsearch

What we’re building
Given several open data sets or dataset apis, the idea is to extract the datasets, transform and load them into an Elasticsearch cluster for fast searches via the Elasticsearch api. Users should be able to type in terms in a text box, google search style, and get instant relevant hits, then they should be able to narrow down their choices using some filtering mechanism. The ultimate vision is to have a more artifact focused search where users can search on a particular dataset, say recalls, and perform more focused searches.
Why build it?
Building it out of curiosity really. I noticed a lot of text heavy datasets were being exposed as APIs by different organizations and agencies but it would be benificial to have a search repository where the open datasets/apis are the initial lnding service. There a few reasons why I wanted to build a full unified search application:
I needed to get familiar with the Elasticsearch DSL, or at least enough of it where I can build these aggregations/facets and filters using a modern web UI framework. The other reason is a learning experience which involves new web tools, different cloud environments for development/hosting and get some real work done with powerful search platform.
The Technology Stack & Architecture
The idea was to decouple the web front end with the server at development time so that it’s possible to fiddle with different Elasticsearch clients to see which was a better fit for the server side API. The technology behind the api that would proxy the Elasticsearch interfaces is written in NodeJS. The choice was between NodeJS and Golang Follow along and i’ll tell you why later.
The infrastructure is composed of Heroku for hosting the web app, mlab for possible user management and metrics storage (this could be Postgres, have not decided) and AWS elasticsearch OR elasticcloud, both are eventually on AWS but one is fully managed by the elastic team and one is fully managed by AWS elasticsearch service.
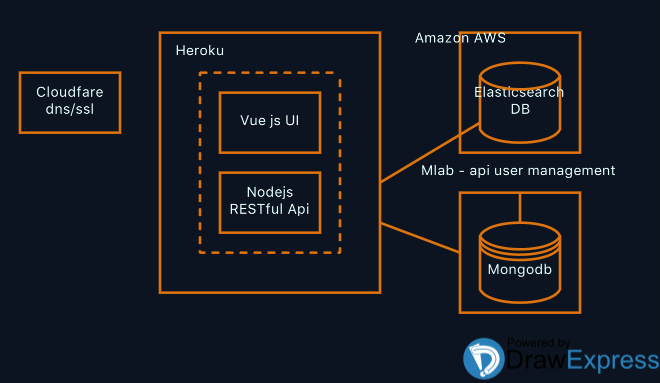
Decision on programming languages and technology stacks
The front end
Following the explosion of javascript serverside tooling and frameworks, i built some basic apps with 3 frameworks/libraries (Angular 2, Aurelia, VueJs) and realized that my decision would be based on the framework that gets me the less frustrated (learning curve), because they all had the same goal, simplify javascript development and management while increasing productivity and performance. All three of these frameworks are fantastic, the support, enthusiasm and community behind them are excellent, i’m not an expert in any of these frameworks but here is the main reason i chose vue.
Angular
Even tough I believe Angular 2 is a nice upgrade from AngularJS with the introduction of Typescript and i understand the goal, the framework demanded me to commit and conform too much to a particular style of building apps. If I were building this app within a large team, specially within an organisation, Angular would be my go to language for because the default design of the framework’s api mirror the n-tier layered architecture and design patterns that developers have been using in Java and C# for a long time.
Writing Angular, the right way, the Angular way can be very elegant and easy to maintain in the long run. Now look at how to get started with Angular: :
Step 1. Set up Your Machine (must have NPM installed)
npm install -g @angular/cli
Step 2. Create new Project
ng new ang-app
Aurelia
Aurelia with typescript was very similar to Angular but it opted for present and future ECMAscript syntax. I thought it was great, if Aurelia had the support of Angular, i would chose Aurelia over Angular for building large apps with large teams within an organisation. The support is fanstastic but depending on the organisation, they tend to go with the products that are backed by the biggest companies. The getting started:
Step 1. Set up Your Machine (must have NPM installed)
npm install -aurelia-cli -g
Step 2. Create new project
au new
Vue
Vue is all about keeping the cognitive mental model of an isolated component in «now memory». The Vue components are self contained, they accept data/commands as inputs, animate and/or produce events and come alive. I hit the ground running pretty fast with Vue and never looked back. the documenation pages have live js fiddle code that you can get quick hands on practice with after reading the concepts. The getting started is as simple as that. Of course to build a full blown single page app, your getting started will look more like the two other previously mentioned framework but the simple version focuses on just the view layer, no routing , no need to have npm or node installed as a pre-requisite. You can also slowly upgrade a legacy application, which are usually written in a composition of JSP/Javascript/Flash or ASP.net/Javascript/Flash etc.
To get started:
Step 1. Drop this reference in a new or existig web project or in js fiddle
<script src="https://cdn.jsdelivr.net/npm/vue"></script>
Step 2. Happy Coding!
Declare the main div tag where the vue instance will interact with the DOM (Document Object Model)
<div id="app">
{{ message }}
</div>
Declare a vue instance in your javascript file and reference the main div tag created earlier
var app = new Vue({
el: '#app',
data: {
message: 'Hello Vue!'
}
})
Serving your html file should now show you
Hello Vue!
Alternatively, use the vue-cli for users familiar with nodejs and it’s build tools. This will allow you to build a full single page app just like Angular and Aurelia’s cli tools.
Step 1. Set up Your Machine (must have NPM installed)
npm install --global vue-cli
Step 2. Create new project
vue init webpack vue-app
Here is a teaser of what the current Vue js based search page looks like. My elasticsearch instance is still local and the api proxy to elasticsearch is not yet stable:

The Elasticsearch proxy APIs
I wanted a dynamic/semi dynamic or lightweight language which means I had to learn something else.
I chose Nodejs because well, Javascript… I originally started with Golang but the offical Go elasticsearch client is not yet mature. There is another open source Go client although it’s highly performant and is constantly improving, my instincts told me to go with elaticsearch.js. It seems a natural fit given the Restful nature of the elasticsearch API. Here is an example of what an elasticsearch query looks like from the elasticsearch Restful API :
1GET /*/_search
2{
3 "query": {
4 "bool": {
5 "must": [
6 {
7 "match": {
8 "_all": "poison"
9 }
10 }
11 ],
12 "filter": {
13 "bool": {
14 "must": [
15
16 {
17 "terms": {
18 "type": [
19 "recall"
20 ]
21
22 }
23 },
24 {
25 "terms": {
26 "category.keyword": [
27 "Consumer Products","Foods, Medicines, Cosmetics"
28 ]
29
30 }
31 },
32
33 {
34 "terms": {
35 "artifactSource": [
36 "cpsc","fda"
37 ]
38
39 }
40 },
41
42
43 {
44 "range": {
45 "artifactDate": {
46 "gte": "1970-09-20",
47 "lte": "2019-09-26"
48 }
49 }
50 }
51 ]
52 }
53 }
54
55 }
56
57
58 },
59 "size":"10",
60
61 "aggregations": {
62 "artifact_type": {
63 "terms": {
64 "field": "type.keyword"
65
66 }
67 },
68 "artifact_category": {
69 "terms": {
70 "field": "category.keyword"
71 }
72 },
73
74 "artifact_source": {
75 "terms": {
76 "field": "artifactSource.keyword"
77 }
78 }
79 }
80}
This elasticsearch query performs a search where the word fire is present, the "match": {
"_all": "poison"
}
predicate tells elasticsearch to look for the word poison in every field in the document that has text data and then perform a filter on the result where the only data that gets return are of type fdarecall AND are between 1970 and 2009. The data is then sorted by type and artifact date. Then an aggregation object is also returned which retrieves the number of indexed documents that meet all the conditions of the aggregation
In SQL syntax the equivalent would roughly be :
SELECT [fields] FROM index_name
WHERE fulltext_field LIKE '%poison%'
AND _type = 'fdarecall'
AND artifactDate BETWEEN '1970-09-20' AND '2009-09-26'
GROUP BY artifact_Source, artifact_type
ORDER BY _type, artifactDate DESC
The only difference is that, this query would NOT run in the SQL engine because you have to specify the fields that are going to be grouped and you can’t really mix aggregation queries with resultset in one simple SQL command. You’de have to write a much more complicated and lenghty query.
We can even reduce the verbosity of the Json queries with the bodybuilder javascript package by writing something like this (not tested yet, i want to make sure i can execute with the raw DSL first) :
bodybuilder()
.query('match', '_all', 'poison')
.Filter('terms', '_type', 'fdarecall')
.andFilter('range', 'artifactDate', [{ to: '2009-09-26' }, { from: '1970-09-20' }])
.sort('_type','desc')
.sort('artifactDate','desc')
.aggregation('terms', 'type.keyword')
.aggregation('terms','artifactSource.keyword')
.build()
Mapping the datasets for indexing
The mapping, transformation etc. of dataset fields to indexes is a stand alone ETL program, once that’s finalized, i will also write a post about it. The basic structure of the initial search index will follow this data contract in order to be included in the home page’s search results:
public interface IArtifact:IDataCategoryType
{
String UUID { get; }
String Title { get; set; }
DateTime ArtifactDate { get; }
string ArtifactSource { get; }
string Description { get; }
string Category { get; }
string FullTextSearch { get;set;}
}